Prečo sa webové pavúky nazývajú počítačovými pavúkmi? Pochopenie webových crawlerov
Zistite, prečo sa webové pavúky nazývajú počítačovými pavúkmi a ako prehľadávajú internet. Objavte, ako fungujú vyhľadávacie crawlery a aký majú význam pre SEO a affiliate marketing.
Prečo sa nazývajú počítačovými pavúkmi? Nazývajú sa počítačovými pavúkmi, pretože "preliezajú" web.
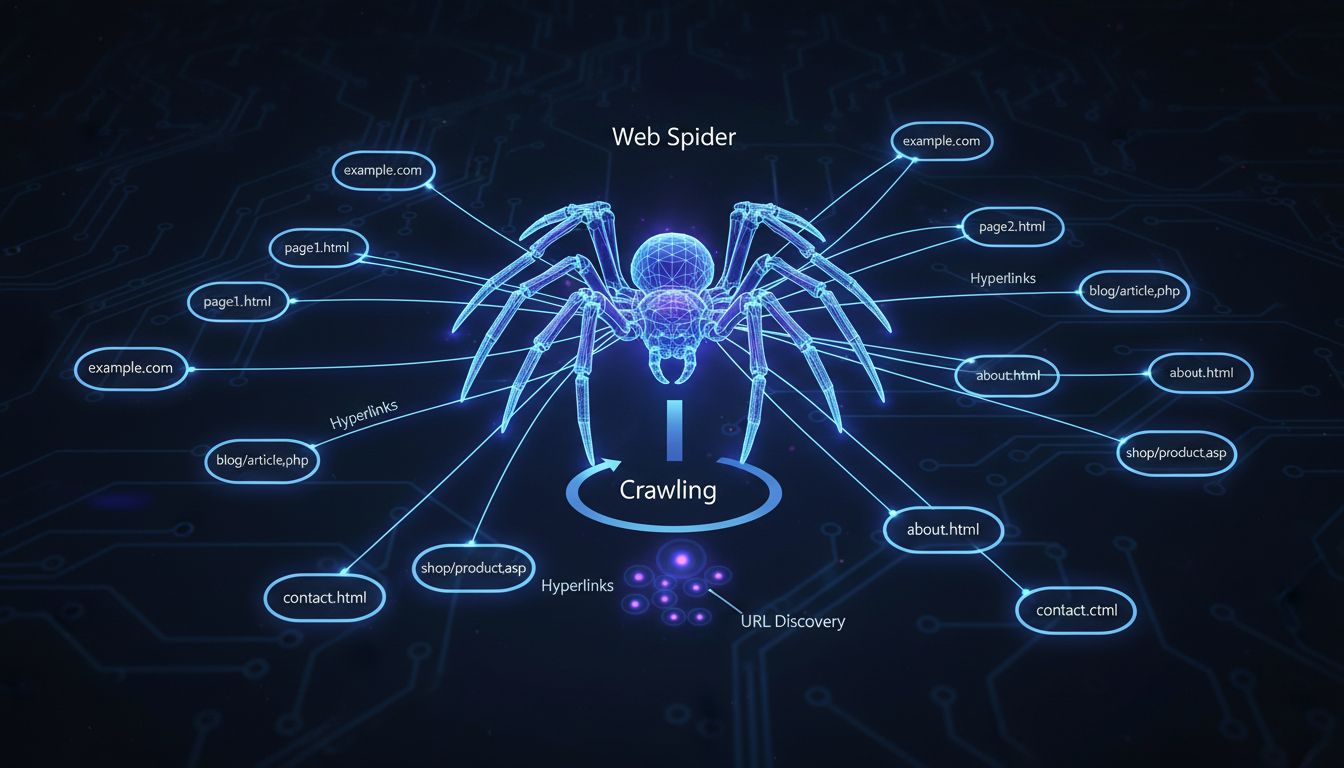
Webové pavúky sa nazývajú počítačovými pavúkmi, pretože "preliezajú" internet nasledovaním hypertextových odkazov z jednej stránky na druhú, podobne ako sa pavúk pohybuje po svojej sieti. Tieto automatizované programy systematicky objavujú webstránky, aby vyhľadávače mohli ich obsah indexovať.
Pochopenie metafory pavúka
Pojem „počítačový pavúk“ pochádza z výstižnej analógie, ktorá dokonale popisuje, ako tieto automatizované programy fungujú na internete. Tak ako skutočný pavúk prechádza po svojej sieti sledujúc vlákna a spojenia, webový pavúk sa pohybuje po internete nasledovaním hypertextových odkazov z jednej webstránky na druhú. Táto metafora sa stala tak intuitívnou, že dnes je štandardným termínom používaným web developermi, SEO špecialistami aj digitálnymi marketérmi po celom svete. Názov vystihuje podstatu správania crawlera spôsobom, ktorý je okamžite zrozumiteľný technickému aj netechnickému publiku. Ak pochopíte tento základný koncept, začnete si vážiť, ako elegantne infraštruktúra internetu kopíruje prírodné systémy v prírode.
Ako webové pavúky prehľadávajú internet
Webové pavúky fungujú systematickým a metodickým procesom, ktorý začína so zoznamom známych počiatočných URL adries. Crawler začne návštevou týchto úvodných stránok a starostlivo skúma ich obsah a štruktúru. Počas spracovania každej stránky pavúk identifikuje všetky hypertextové odkazy na stránke a pridá ich do zoznamu URL, ktoré má navštíviť nabudúce. Tento proces sa neustále opakuje, vďaka čomu pavúk postupne preniká hlbšie do webu pri každej iterácii. Pavúk si týmto spôsobom vytvára mapu internetu podľa týchto spojení, podobne ako objaviteľ mapuje nové územie sledovaním ciest a chodníčkov. Tento systematický prístup zabezpečuje, že vyhľadávače môžu objavovať a zaznamenávať milióny nových stránok každý jeden deň.
Komponent crawlera
Funkcia
Účel
Fronta URL
Ukladá zoznam stránok na návštevu
Organizuje poradie prehľadávania
Parser
Číta obsah stránky a HTML
Extrahuje odkazy a metadáta
Indexátor
Ukladá informácie o stránkach
Vytvára vyhľadávateľnú databázu
Schedulér
Určuje frekvenciu prehľadávania
Spravuje rozdelenie zdrojov
User-Agent
Identifikuje crawler
Komunikuje so servermi
Technický proces za webovým prehľadávaním
Skôr než webový pavúk začne svoje prehľadávanie, vývojári musia stanoviť jasné, vopred definované inštrukcie, ktoré riadia jeho správanie. Tieto inštrukcie určujú, ktoré stránky prehľadávať, ako často sa na ne vracať a aké informácie z každej stránky extrahovať. Crawler potom tieto pokyny vykonáva automaticky podľa zadaného algoritmu. Keď pavúk navštívi webstránku, najprv skontroluje súbor robots.txt, čo je textový súbor so špecifickými pravidlami pre prístup crawlerov. Tento protokol, známy ako robot exclusion protocol, umožňuje majiteľom webov určiť, ktoré časti ich stránok majú byť prehľadávané a ktoré nie. Informácie získané crawlerom závisia výhradne od konkrétnych inštrukcií, preto je fáza nastavenia kľúčová na dosiahnutie požadovaných výsledkov.
Rôzne typy webových pavúkov
Webové pavúky existujú v rôznych formách, pričom každý je navrhnutý na špecifické účely a aplikácie. Najznámejšie sú vyhľadávacie pavúky ako Googlebot, ktoré používajú hlavné vyhľadávače na objavovanie a indexovanie webstránok pre výsledky vyhľadávania. Naopak, špecializované crawlery obmedzujú svoj záber na konkrétne témy alebo oblasti internetu a vytvárajú detailné indexy špecifického obsahu. Analytické pavúky pomáhajú webmasterom monitorovať vlastné weby sledovaním metrík ako návštevnosť, nefunkčné odkazy a výkon stránok. Pavúky na porovnávanie cien automaticky zhromažďujú cenové informácie od viacerých predajcov, vďaka čomu môžu porovnávacie weby poskytovať aktuálne trhové údaje. Pavúky na overovanie e-mailov zas overujú e-mailové adresy a kontrolujú ich doručiteľnosť. Každý typ pavúka má svoju jedinečnú úlohu v digitálnom ekosystéme a pochopenie týchto rozdielov pomáha majiteľom stránok optimalizovať svoje weby pre vhodné crawlery.
Prečo sú vyhľadávače závislé od webových pavúkov
Vyhľadávače nemôžu fungovať bez webových pavúkov, pretože tieto automatizované programy sú zodpovedné za objavovanie nového obsahu a udržiavanie aktuálnych indexov. Keď zadáte vyhľadávací dopyt, vyhľadávač v skutočnosti neprehľadáva živý internet v reálnom čase. Namiesto toho vyhľadáva v indexe, ktorý bol vytvorený webovými pavúkmi, ktoré predtým navštívili a zaznamenali miliardy stránok. Bez pavúkov by vyhľadávače nevedeli, aký obsah na internete existuje alebo ako ho usporiadať na vyhľadávanie. Schopnosť pavúka sledovať hypertextové odkazy znamená, že nové stránky môžu byť objavené automaticky bez potreby manuálneho pridania. Práve tento automatizovaný objavovací proces robí internet vyhľadávateľným a dostupným miliardám používateľov na celom svete. Efektivita a rýchlosť webových pavúkov priamo ovplyvňujú, ako rýchlo sa nový obsah objaví vo výsledkoch vyhľadávania.
Význam webových pavúkov pre SEO a digitálny marketing
Pre majiteľov webov a digitálnych marketérov je pochopenie webových pavúkov kľúčové, pretože práve títo crawlery rozhodujú, či sa váš obsah zobrazí vo výsledkoch vyhľadávania. Ak vyhľadávací pavúk nedokáže prehľadať vašu stránku, vaše stránky nebudú indexované a neobjavia sa vo výsledkoch vyhľadávania, bez ohľadu na kvalitu obsahu. Preto sa SEO špecialisti zameriavajú na to, aby boli weby „prístupné pre crawlery“ – správnou štruktúrou webu, rýchlym načítaním a jasnou navigáciou. Affiliate marketéri obzvlášť profitujú z poznania správania pavúkov, pretože to priamo ovplyvňuje, ako sú ich affiliate stránky objavované a hodnotené. PostAffiliatePro si uvedomuje, že úspešné affiliate programy závisia od viditeľnosti, a naša platforma vám pomáha optimalizovať vašu affiliate sieť tak, aby vyhľadávacie pavúky mohli jednoducho objaviť a indexovať váš affiliate obsah. Ak sprístupníte svoje affiliate stránky crawlerom, zvýšite šancu, že váš program objavia potenciálni partneri a zákazníci cez organické vyhľadávanie.
Správa a kontrola aktivity webových pavúkov
Majitelia webov majú k dispozícii viacero nástrojov na správu toho, ako s ich stránkami interagujú webové pavúky. Súbor robots.txt je hlavný mechanizmus na komunikáciu preferencií crawlerov, vďaka ktorému môžete určiť, ktoré stránky sa majú prehľadávať a ktorým sa má vyhnúť. Meta tag noindex poskytuje ďalšiu kontrolu tým, že zabraňuje indexovaniu konkrétnych stránok, aj keď budú prehľadané. Pre stránky, ktoré možno prehľadávať, ale nemajú byť indexované, je možné na odkazy použiť atribút nofollow, aby pavúky tieto konkrétne spojenia nesledovali. Majitelia webov môžu tiež využiť Google Search Console a ďalšie nástroje pre webmasterov na monitorovanie aktivity crawlerov a identifikáciu problémov, ktoré by mohli brániť správnemu indexovaniu. Je však dôležité poznamenať, že aj keď tieto nástroje pomáhajú spravovať legitímnych vyhľadávacích pavúkov, škodlivé boty a scrapery môžu tieto pokyny ignorovať. Preto mnohé weby zavádzajú aj dodatočné bezpečnostné opatrenia a systémy na správu botov, aby chránili svoj obsah pred škodlivou činnosťou crawlerov a zároveň umožnili prístup prospešným pavúkom.
Rozdiel medzi pavúkmi a scrapermi
Aj keď webové pavúky a scrapery oboje automaticky zhromažďujú údaje z webstránok, slúžia veľmi odlišným účelom a riadia sa inými etickými zásadami. Webové pavúky, najmä tie používané vyhľadávačmi, dodržiavajú protokol robots.txt a rešpektujú preferencie vlastníkov webov, ktoré časti sa majú prehľadávať. Scrapery naopak často tieto pokyny ignorujú a kopírujú celé stránky obsahu, ktoré následne publikujú inde, čo môže byť porušením autorských práv a krádežou duševného vlastníctva. Pavúky typicky zhromažďujú a organizujú metadáta stránok, zatiaľ čo scrapery kopírujú celý viditeľný obsah. Vyhľadávacie pavúky sú vo všeobecnosti považované za prospešné, pretože pomáhajú webom získať viditeľnosť, kým scrapery sú často vnímané ako škodlivé, pretože kradnú obsah a môžu zhoršiť výkon webu. Pochopenie tohto rozdielu je dôležité pre majiteľov stránok, ktorí musia rozlišovať medzi legitímnou návštevnosťou crawlerov a škodlivou aktivitou botov. PostAffiliatePro pomáha affiliate manažérom monitorovať a spravovať návštevnosť na ich affiliate stránkach, aby mali istotu, že legitímni pavúky majú prístup k obsahu, zatiaľ čo chránia pred škodlivým scrapingom.
Maximalizujte viditeľnosť svojej affiliate siete
Tak ako webové pavúky objavujú a indexujú váš obsah, PostAffiliatePro vám pomáha objaviť a spravovať celú vašu affiliate sieť. Sledujte každú interakciu crawlera a optimalizujte výkon svojho affiliate programu s našou špičkovou platformou.
Prečo sa webové prehľadávače nazývajú pavúky? Pochopenie technológie indexovania webu
Zistite, prečo sa webové prehľadávače nazývajú pavúky, ako fungujú a akú kľúčovú úlohu zohrávajú pri indexovaní vyhľadávačov. Objavte technické mechanizmy webov...