
Crawlery a ich úloha v hodnotení vyhľadávačov
Crawlery zhromažďujú dáta a informácie z internetu návštevou webových stránok a čítaním ich obsahu. Zistite o nich viac.
5 min čítania
SEO
Crawlers
+4

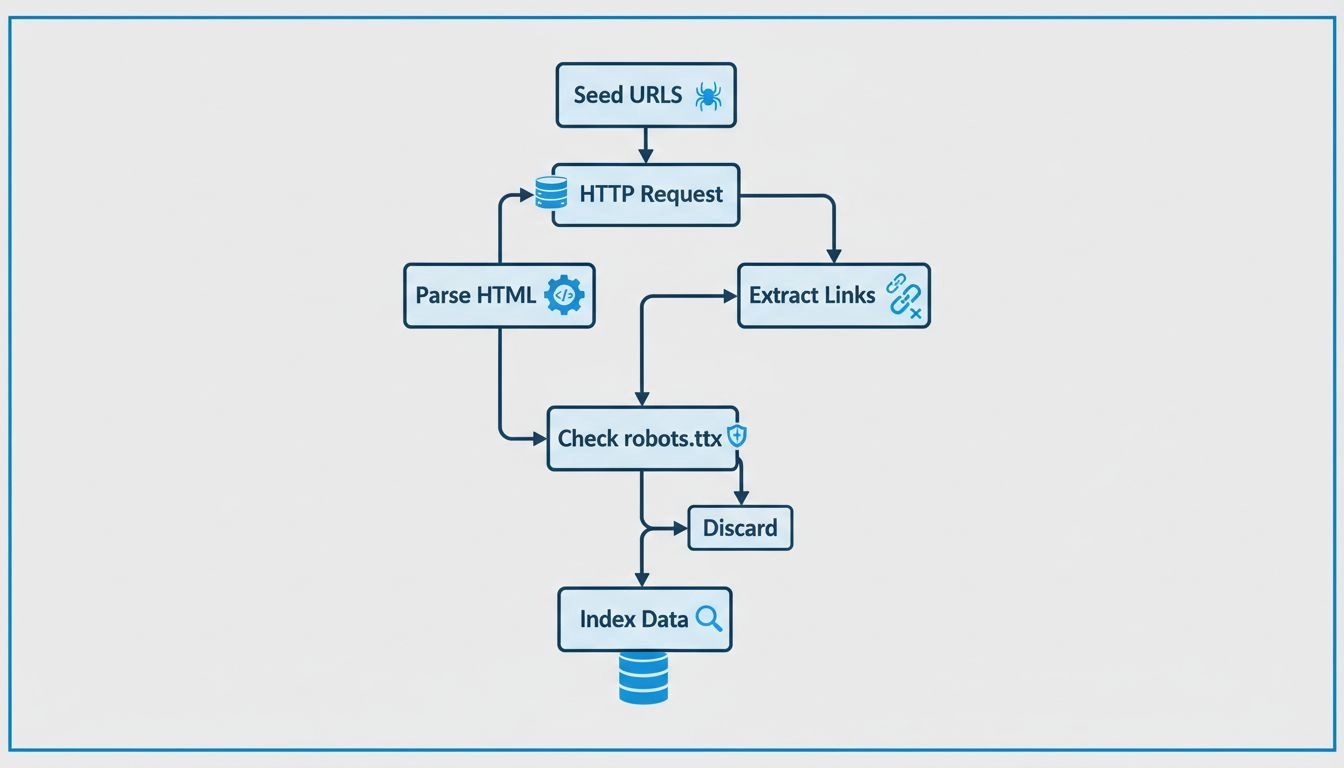
Zistite, ako fungujú webové prehľadávače – od počiatočných URL adries až po indexovanie. Pochopte technický proces, typy prehľadávačov, pravidlá robots.txt a vplyv prehľadávačov na SEO a affiliate marketing.
Webové prehľadávače fungujú tak, že posielajú HTTP požiadavky na webové stránky, začínajú od počiatočných URL adries, sledujú hypertextové odkazy na objavovanie nových stránok, analyzujú HTML obsah na extrakciu informácií, rešpektujú pravidlá robots.txt a ukladajú získané dáta do prehľadávateľných indexov. Systematicky navštevujú stránky, extrahujú metadáta a odkazy a celý proces opakujú, aby boli databázy vyhľadávačov aktuálne.
Webové prehľadávače, známe aj ako „spideri“ alebo „boti“, sú automatizované programy, ktoré systematicky prehliadajú internet s cieľom objavovať, sťahovať a analyzovať webový obsah. Títo inteligentní agenti tvoria základnú infraštruktúru vyhľadávačov, vďaka čomu môžu platformy ako Google, Bing a ďalšie vyhľadávacie služby vytvárať komplexné indexy miliárd webových stránok. Hlavným cieľom webových prehľadávačov je zhromažďovať a organizovať informácie z webov, aby vyhľadávače mohli rýchlo poskytnúť relevantné výsledky pri vyhľadávaní používateľov. Bez prehľadávačov by vyhľadávače nemali spôsob, ako objaviť nový obsah alebo udržiavať svoje indexy aktuálne s najnovšími informáciami na internete.
Význam webových prehľadávačov siaha ďaleko za jednoduché vyhľadávanie. Sú základom pre množstvo digitálnych aplikácií vrátane porovnávačov cien, agregátorov obsahu, platforiem pre prieskum trhu, SEO analytických nástrojov a služieb na archiváciu webov. Pre affiliate marketérov a prevádzkovateľov sietí, ako sú používatelia PostAffiliatePro, je pochopenie fungovania prehľadávačov zásadné pre zabezpečenie toho, aby affiliate obsah, produktové stránky a propagačné materiály boli správne objavené a zaindexované vyhľadávačmi. Táto viditeľnosť priamo ovplyvňuje organickú návštevnosť, generovanie leadov a v konečnom dôsledku aj príležitosti na získanie provízií.
Webové prehľadávače nasledujú metodický a štruktúrovaný proces na systematické preskúmanie internetu. Proces začína pomocou počiatočných URL adries (seed URLs), čo sú známe východiskové body – napríklad hlavné stránky, XML sitemap alebo už predtým prehľadané stránky. Tieto URL slúžia ako vstupný bod pre cestu prehľadávača webom. Prehľadávač si udržiava zoznam URL adries na navštívenie, tzv. „frontu prehľadávania“ (crawl frontier), ktorá sa neustále rozrastá objavovaním nových odkazov počas prehľadávania.
Keď prehľadávač dosiahne konkrétnu URL, odošle HTTP požiadavku na webový server, ktorý túto stránku hosťuje. Server odpovie zaslaním HTML obsahu stránky, podobne ako keď stránku navštívite cez prehliadač. Prehľadávač následne analyzuje HTML kód, aby extrahoval hodnotné informácie vrátane textu stránky, meta tagov (napríklad titulok a popis), obrázkov, videí a predovšetkým hypertextových odkazov na ďalšie stránky. Extrakcia odkazov je kľúčová, pretože umožňuje prehľadávaču objavovať nové, zatiaľ nenavštívené URL adresy, ktoré sa následne pridajú do fronty na neskoršiu návštevu.
| Fáza procesu prehľadávača | Popis | Kľúčové činnosti |
|---|---|---|
| Inicializácia | Spustenie procesu prehľadávania | Načítanie počiatočných URL, inicializácia fronty |
| Požiadavka a získanie obsahu | Stiahnutie obsahu stránky | Odoslanie HTTP požiadaviek, prijatie HTML odpovedí |
| Analýza HTML | Parsovanie štruktúry stránky | Extrakcia textu, metadát, odkazov, médií |
| Extrakcia odkazov | Hľadanie nových URL | Identifikácia hypertextových odkazov, pridanie do fronty |
| Kontrola robots.txt | Rešpektovanie pravidiel webu | Overenie povolení na prehľadávanie pred návštevou |
| Ukladanie obsahu | Uloženie informácií | Indexovanie dát do prehľadávateľnej databázy |
| Prioritizácia | Určenie ďalších stránok | Hodnotenie URL podľa dôležitosti a relevantnosti |
| Opakovanie | Pokračovanie cyklu | Spracovanie ďalšej URL vo fronte |
Pred návštevou novej URL na doméne si zodpovedné prehľadávače kontrolujú súbor robots.txt umiestnený v koreňovom adresári domény. Tento súbor obsahuje inštrukcie, ktorými majitelia webov určujú, ktoré stránky môžu byť prehľadávané a ktorým sa má prehľadávač vyhnúť. Napríklad majiteľ webu môže použiť robots.txt na zabránenie prístupu prehľadávačov k citlivým stránkam, duplicitnému obsahu alebo častiam náročným na serverové zdroje. Väčšina legitímnych prehľadávačov tieto pokyny rešpektuje, aby udržiavali dobré vzťahy s majiteľmi webov a nespôsobovali problémy s výkonom stránok.
Nastavte pokročilé sledovanie za pár minút. Kreditná karta nie je potrebná.
Moderné webové prehľadávače sa výrazne vyvinuli, aby zvládli komplexnosť dnešných webov. Mnohé stránky dnes používajú JavaScript na dynamické generovanie obsahu po načítaní stránky, takže počiatočná HTML odpoveď neobsahuje všetok obsah stránky. Pokročilé prehľadávače preto využívajú headless prehliadače na vykreslenie JavaScriptu a zachytenie dynamicky načítaného obsahu, ktorý by tradičné prehľadávače nevideli. Táto schopnosť je nevyhnutná na prehľadávanie single-page aplikácií, interaktívnych dashboardov či moderných webových aplikácií s veľkým podielom klientského renderovania.
Prehľadávače implementujú sofistikované algoritmy prioritizácie na efektívne využitie svojho „crawl budgetu“ – obmedzeného počtu stránok, ktoré môžu v danom čase prehľadať. Tieto algoritmy zohľadňujú viacero faktorov, ako je autorita stránky (daná kvalitou a počtom spätných odkazov), štruktúra interného prelinkovania, aktuálnosť obsahu, objem návštevnosti a reputácia domény. Stránky s vysokou autoritou a často aktualizovaným obsahom sú prehľadávané častejšie, kým menej dôležité alebo statické stránky môžu byť navštevované zriedkavejšie alebo preskočené. Táto inteligentná prioritizácia zabezpečuje, že prehľadávače sústredia zdroje na najhodnotnejší a najdynamickejší obsah.
Oneskorenie prehľadávania a obmedzenie rýchlosti sú dôležité mechanizmy, ktoré zabraňujú preťaženiu webových serverov prehľadávačmi. Zodpovedné prehľadávače medzi požiadavkami robia pauzy a rešpektujú direktívy pre crawl-delay v robots.txt. Takéto ohľaduplné správanie chráni výkon a používateľskú skúsenosť webov, pretože návštevnosť z prehľadávačov nevyťažuje nadmerne serverové zdroje. Weby, ktoré sa načítavajú pomaly alebo vracajú chyby, môžu byť prehľadávané menej často – prehľadávače totiž automaticky spomalia, aby nespôsobili problémy.
Rôzne typy webových prehľadávačov slúžia v digitálnom ekosystéme špecifickým účelom. Všeobecné webové prehľadávače nasadzujú veľké vyhľadávače na plošné prehľadávanie celého internetu bez výberu, aby vytvorili komplexné indexy pre výsledky vyhľadávania. Tieto prehľadávače sú navrhnuté pre maximálne pokrytie a nepretržite objavujú nový obsah a aktualizujú existujúce indexy. Vertikálne alebo špecializované prehľadávače sa sústreďujú na konkrétne odvetvia alebo typy obsahu – napríklad prehľadávače pracovných ponúk, ktoré prechádzajú pracovné portály, porovnávače cien zbierajúce cenové údaje z e-shopov alebo vedecké prehľadávače indexujúce akademické publikácie.
Inkrementálne prehľadávače sa špecializujú na efektivitu – zameriavajú sa len na nový alebo nedávno zmenený obsah namiesto opakovaného prehľadávania celého webu. Tento prístup podstatne znižuje záťaž na server a spotrebu dát a zároveň udržiava indexy pomerne aktuálne. Zamerané prehľadávače využívajú algoritmy na hľadanie obsahu podľa konkrétnych tém alebo kľúčových slov, pričom inteligentne uprednostňujú stránky s relevantnými informáciami. Prehľadávače v reálnom čase neustále monitorujú weby a aktualizujú zozbierané údaje v reálnom alebo takmer reálnom čase, vďaka čomu sú ideálne na agregáciu správ a monitoring sociálnych sietí.
Paralelné a distribuované prehľadávače predstavujú infraštruktúrne najnáročnejšie riešenia. Paralelné prehľadávače fungujú na viacerých strojoch alebo vláknach naraz, čím dramaticky zrýchľujú a zvyšujú objem prehľadávania. Distribuované prehľadávače rozkladajú záťaž medzi viaceré servery alebo dátové centrá, vďaka čomu môžu efektívne spracovať obrovské množstvo dát. Veľké vyhľadávače ako Google využívajú práve distribuované architektúry na zvládnutie miliárd stránok na internete.
Buďte prvý, kto sa dozvie o nových funkciách a aktualizáciách produktu.
Webové prehľadávače zohrávajú zásadnú úlohu v optimalizácii pre vyhľadávače, pretože rozhodujú o tom, ktoré stránky budú zaindexované a ako vyhľadávače váš obsah pochopia. Ak sa prehľadávače nedostanú k vašim stránkam, tieto sa v hľadaní neobjavia, nech by boli akokoľvek kvalitné či relevantné. Bežné problémy s prehľadávaním, ktoré bránia správnemu indexovaniu, zahŕňajú blokovanie stránok v robots.txt, rozbité interné odkazy vedúce na 404 chyby, pomalé načítanie stránok spôsobujúce timeouty a problémy s renderovaním JavaScriptu, ktoré bránia prehľadávaču vidieť dynamicky generovaný obsah.
Majitelia webov môžu optimalizovať prístup prehľadávačov viacerými kľúčovými stratégiami. Prehľadná architektúra webu s logickou navigáciou pomáha prehľadávačom pochopiť vzťahy medzi stránkami a ich dôležitosť. Interné prelinkovanie signalizuje prehľadávačom, ktoré stránky sú najdôležitejšie a zároveň pomáha efektívne rozdeľovať crawl budget po webe. XML sitemap výslovne uvádza všetky dôležité stránky, čím zabezpečuje, že prehľadávač nevynechá žiadny obsah ani na rozsiahlych či komplexných weboch. Rýchle načítavanie stránok motivuje prehľadávače navštíviť viac stránok v rámci vyhradeného crawl budgetu, zatiaľ čo čerstvý a pravidelne aktualizovaný obsah signalizuje, že web si zaslúži častejšie návštevy prehľadávača.
Pre affiliate marketérov využívajúcich platformy ako PostAffiliatePro je zabezpečenie správneho prístupu prehľadávačov rozhodujúce pre získavanie organickej návštevnosti na affiliate obsah. Keď sú vaše produktové stránky, porovnávacie články a promo materiály správne prehľadané a zaindexované, majú šancu umiestniť sa vo výsledkoch vyhľadávania a osloviť relevantné publikum. Slabá prehľadateľnosť môže znamenať zmeškané príležitosti na indexáciu a nižšiu viditeľnosť vašich affiliate ponúk.
Majitelia webov majú k dispozícii viacero nástrojov na riadenie interakcií prehľadávačov so svojimi stránkami. Súbor robots.txt je základný nástroj a obsahuje direktívy určujúce, ktoré user-agenty (typy prehľadávačov) môžu pristupovať do konkrétnych častí webu. Správne nastavený robots.txt bráni plytvaniu zdrojov na duplicitný obsah, testovacie prostredia alebo stránky náročné na zdroje, pričom umožňuje voľný prístup k dôležitému obsahu. Meta tag robots umiestnený v HTML konkrétnej stránky poskytuje kontrolu na úrovni stránky – umožňuje napríklad vylúčiť konkrétne stránky z indexovania alebo ignorovať ich odkazy.
Attribut nofollow v odkazoch dáva prehľadávačom pokyn, aby konkrétne hypertextové odkazy nesledovali, čo je užitočné napríklad pri odkazoch na nedôveryhodné externé weby alebo používateľský obsah. Tieto kontrolné mechanizmy umožňujú majiteľom webov detailne riadiť správanie prehľadávačov a zároveň udržiavať dobré vzťahy s vyhľadávačmi. Je však dôležité uvedomiť si, že škodlivé scraperské alebo agresívne boty tieto pokyny často ignorujú, preto sú niekedy potrebné aj ďalšie bezpečnostné opatrenia ako obmedzenie rýchlosti či detekcia botov.
Pre prevádzkovateľov affiliate sietí a marketérov má pochopenie správania prehľadávačov priamy vplyv na úspech podnikania. Práve prehľadávače rozhodujú o viditeľnosti produktových stránok, porovnávacieho obsahu a promo materiálov vo vyhľadávačoch. Ak používatelia PostAffiliatePro optimalizujú svoje affiliate weby pre správne prehľadávanie, zvyšujú šancu, že ich obsah vyhľadávače objavia a umiestnia na relevantné kľúčové slová. Táto organická viditeľnosť privádza na affiliate ponuky kvalifikovanú návštevnosť, čím rastú príležitosti na konverziu aj výšku provízií.
Affiliate siete profitujú z aktivity prehľadávačov viacerými spôsobmi. Prehľadávače vyhľadávačov pomáhajú rozširovať affiliate obsah naprieč internetom, čo zvyšuje povedomie o značke a dosah. Prehľadávače zároveň umožňujú porovnávačom cien a agregátorom obsahu objavovať a propagovať affiliate produkty, čím sa otvárajú ďalšie zdroje návštevnosti. Affiliate marketéri si však musia dať pozor aj na škodlivé prehľadávače a scrapers, ktoré môžu kopírovať affiliate obsah alebo sa pokúšať o podvodné kliky. Implementácia správneho obmedzenia rýchlosti, detekcie botov a ochrany obsahu pomáha chrániť integritu affiliate siete pri zachovaní funkčnosti legitímnych prehľadávačov.
PostAffiliatePro poskytuje komplexné sledovanie a reportovanie, ktoré výborne dopĺňa optimalizáciu prehľadávačov. Ak zabezpečíte, že váš affiliate obsah je správne prehľadávaný a indexovaný a zároveň využijete pokročilé sledovanie a analytiku PostAffiliatePro, maximalizujete viditeľnosť aj ziskovosť svojej affiliate siete. Platforma vám v reálnom čase poskytuje prehľad o províziách a inteligentné reporty, vďaka ktorým zistíte, cez ktoré affiliate kanály prichádza najhodnotnejšia návštevnosť, a môžete tak zefektívniť svoju sieťovú stratégiu.
Rovnako ako webové prehľadávače systematicky objavujú a indexujú obsah, PostAffiliatePro systematicky sleduje a optimalizuje vaše affiliate vzťahy. Naša platforma poskytuje sledovanie v reálnom čase, komplexné reporty a inteligentnú správu provízií, aby ste si vybudovali prosperujúcu affiliate sieť.
Crawlery zhromažďujú dáta a informácie z internetu návštevou webových stránok a čítaním ich obsahu. Zistite o nich viac.
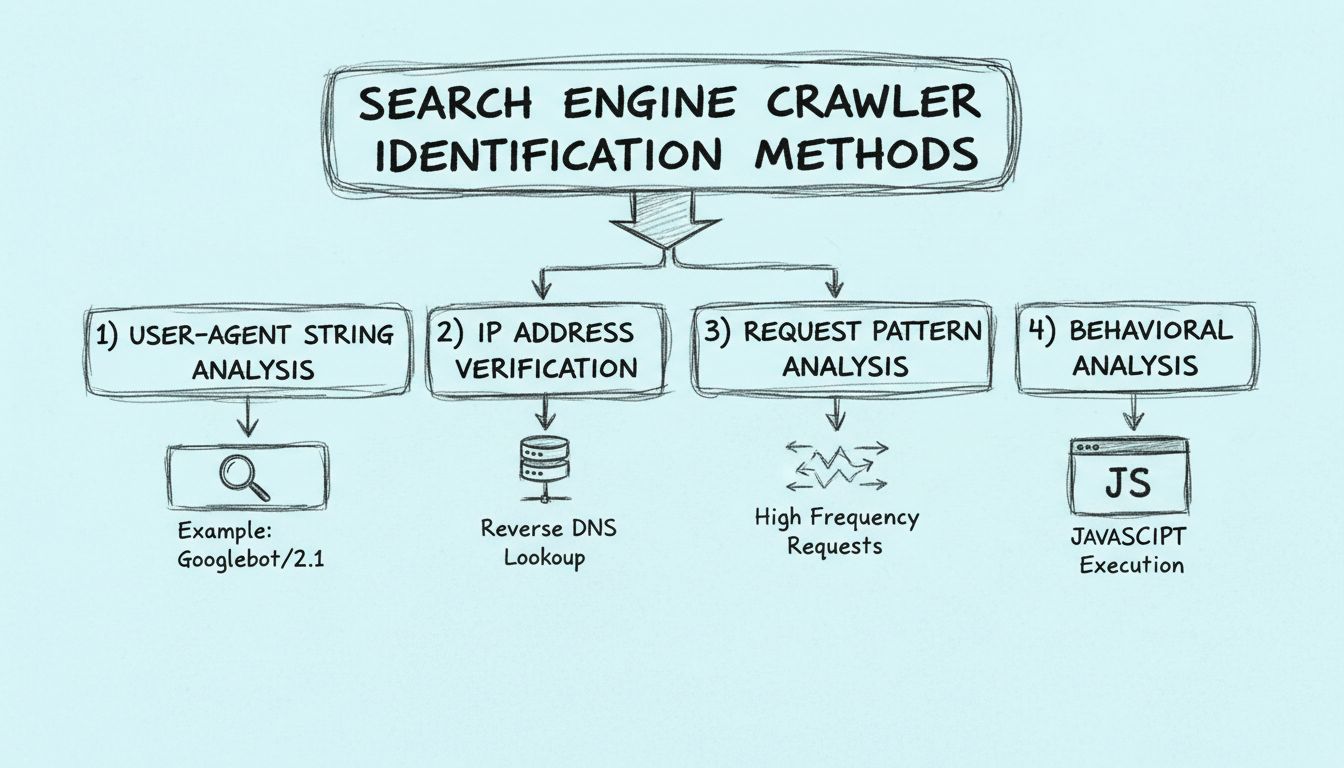
Zistite, ako identifikovať prehľadávače vyhľadávačov pomocou user-agent stringov, IP adries, vzorov požiadaviek a analýzy správania. Základný sprievodca pre web...
Vyhľadávač je softvér vytvorený na uľahčenie vyhľadávania na internete pre používateľov. Prehľadáva milióny stránok a poskytuje najrelevantnejšie výsledky....
Pridajte sa k našej komunite spokojných klientov a poskytujte vynikajúcu zákaznícku podporu s Post Affiliate Pro.
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.