
SEO pavúky: Prečo sú dôležité pre vašu stránku
Pavúky sú boti vytvorení na spamovanie, ktoré môžu vašej firme spôsobiť veľa problémov. Zistite o nich viac v článku.
4 min čítania
SEO
DigitalMarketing
+3

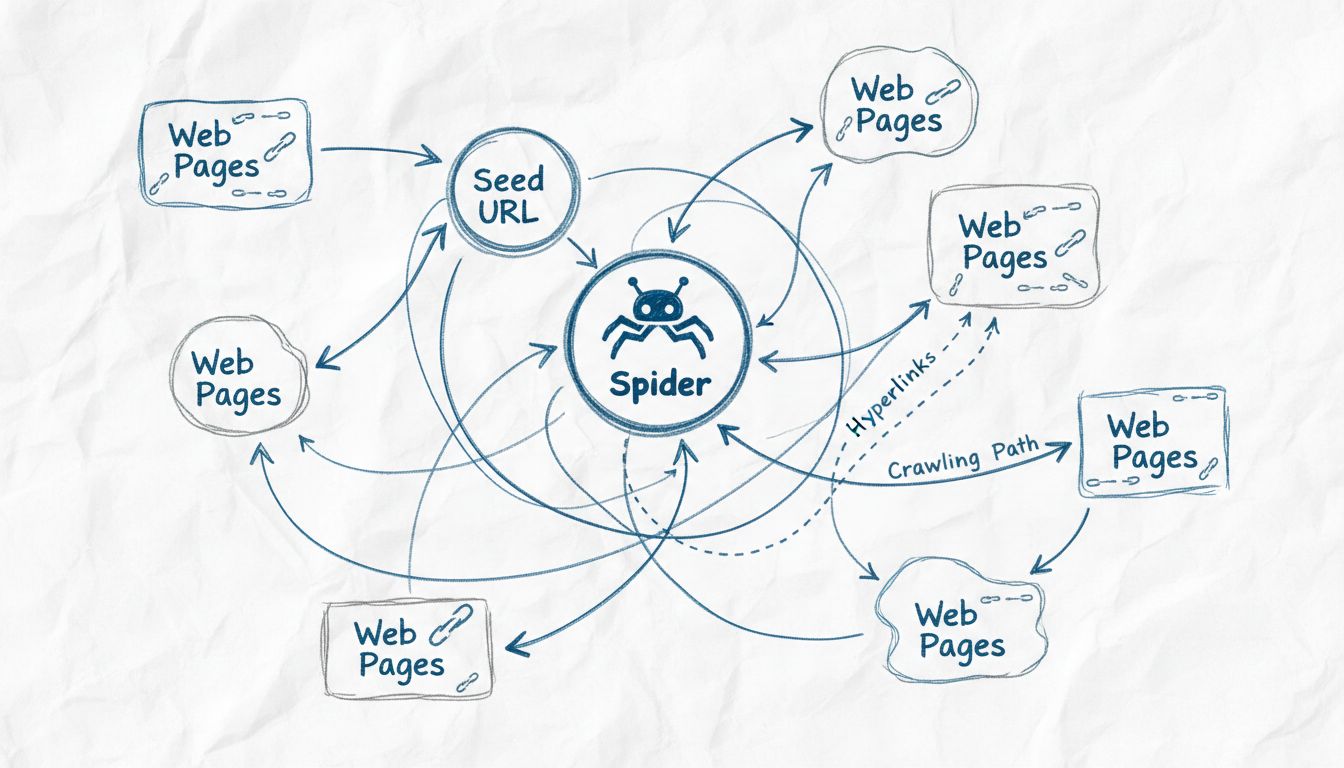
Zistite, prečo sa webové prehľadávače nazývajú pavúky, ako fungujú a akú kľúčovú úlohu zohrávajú pri indexovaní vyhľadávačov. Objavte technické mechanizmy webového prehľadávania v roku 2025.
Webové prehľadávače sa nazývajú pavúky, pretože systematicky prechádzajú web, sledujúc odkazy z jednej stránky na druhú, podobne ako pavúk prechádza svoju sieť. Termín 'pavúk' je výstižnou metaforou pre tieto automatizované roboty, ktoré prechádzajú prepojenú sieť webových stránok, aby objavili, indexovali a organizovali webový obsah pre vyhľadávače.
Termín “pavúk” pre webové prehľadávače pochádza z dôvtipnej metaforickej paralely medzi tým, ako tieto automatizované roboty navigujú internet, a tým, ako skutočné pavúky prechádzajú svoje siete. Rovnako ako pavúk tká zložitú sieť na zachytenie a organizovanie informácií o svojom prostredí, webové prehľadávače (pavúky) prechádzajú prepojenú sieť hypertextových odkazov naprieč celosvetovou sieťou, aby objavili, analyzovali a usporiadali digitálny obsah. Metafora je obzvlášť výstižná, pretože obe entity pracujú systematicky v rámci zložitých sietí, sledujú cestičky, aby dosiahli nové miesta a získali informácie. Toto pomenovanie sa v technológiách tak vžilo, že pojmy “pavúk”, “prehľadávač” a “bot” sa dnes používajú zameniteľne pri diskusii o technológii indexovania webu. Vizuálna a konceptuálna podobnosť medzi pavúčou sieťou a štruktúrou internetu robí túto terminológiu intuitívnou a zapamätateľnou pre technických odborníkov aj bežných používateľov.
Webové pavúky fungujú na sofistikovanom, no systematickom procese, ktorý začína jedným vstupným bodom nazývaným “seed URL” (počiatočná adresa). Z tohto východiskového miesta pavúk analyzuje HTML kód stránky a extrahuje všetky odkazy prítomné na stránke. Následne tieto odkazy sleduje na nové stránky a proces neustále opakuje, čím rozširuje svoj dosah po webe. Tento metodický prístup umožňuje pavúkom objaviť milióny prepojených stránok bez potreby manuálneho vedenia alebo ľudského zásahu. Pavúk si udržiava tzv. “crawl frontier” (frontu prehľadávania), čo je v podstate zoznam adries URL, ktoré boli objavené, ale ešte neboli navštívené. Na základe špecifických politík a algoritmov prehľadávania pavúk určuje, ktoré adresy navštívi ako ďalšie, pričom zohľadňuje faktory ako dôležitosť stránky, frekvenciu aktualizácií a relevantnosť pre ciele indexovania vyhľadávača.
Nastavte pokročilé sledovanie za pár minút. Kreditná karta nie je potrebná.
Moderné webové pavúky sú postavené na sofistikovanej technickej architektúre, ktorá im umožňuje efektívne spracovávať obrovské množstvá dát. Medzi základné komponenty webového prehľadávača patrí systém správy fronty adries URL, ktorý organizuje a priorizuje adresy na prehľadávanie; mechanizmus sťahovania, ktorý rýchlo sťahuje obsah stránok; parsovací modul, ktorý extrahuje odkazy a metadáta z HTML; a indexačný systém, ktorý uchováva spracované informácie pre vyhľadávanie. Pavúky musia taktiež dodržiavať “politeness policies” (zásady ohľaduplnosti), aby nepreťažili cieľové servery nadmerným počtom požiadaviek, opakovacie politiky určujúce, ako často sa majú stránky znova prehľadávať, a výberové politiky, ktoré určujú, ktoré odkazy sú najhodnotnejšie na sledovanie. Súčasné pavúky zvládajú aj JavaScript a AJAX obsah, hoci stále uprednostňujú štandardný HTML pre spoľahlivé objavovanie obsahu. Distribuovaná povaha moderného prehľadávania znamená, že veľké pavúky bežia súčasne na viacerých serveroch, čo im umožňuje paralelne prehľadávať rôzne weby a dramaticky zvyšovať efektivitu a dosah.
Hoci sa pojmy “pavúk” a “prehľadávač” často používajú zameniteľne, treba pochopiť, že ide o tú istú technológiu s rôznymi pomenovaniami. Webové pavúky sa však výrazne líšia od scraperov, ktoré si niektorí zamieňajú s prehľadávačmi. Hlavný rozdiel spočíva v ich účele a rozsahu: webové prehľadávače sa zameriavajú na všeobecné získavanie informácií o webových stránkach a ich štruktúre, sledujú odkazy naprieč webom, aby vytvorili komplexné indexy. Pavúky používané vyhľadávačmi sa sústreďujú na indexovanie textového obsahu, aby bol vyhľadateľný a objaviteľný. Scraperi naopak slúžia na cielené získavanie konkrétnych údajov z webov, ako sú ceny produktov, kontakty alebo recenzie. Scraperi sa zameriavajú spravidla na konkrétne weby alebo typy dát, nie na široké prehľadávanie webu. Navyše prehľadávače a pavúky vo všeobecnosti rešpektujú súbory robots.txt a podmienky používania webu, zatiaľ čo scraperi môžu fungovať aj bez týchto obmedzení. Pochopenie týchto rozdielov je dôležité pre vlastníkov stránok a vývojárov, ktorí potrebujú riadiť, ako ich obsah pristupujú a indexujú automatizované systémy.
Buďte prvý, kto sa dozvie o nových funkciách a aktualizáciách produktu.
Webové pavúky sú absolútne kľúčové pre fungovanie vyhľadávačov a poskytovanie hodnoty používateľom na celom svete. Bez toho, aby pavúky neustále prehľadávali a indexovali webový obsah, by vyhľadávače nemali ako zistiť, aké stránky existujú, aký obsah obsahujú ani aký je jeho význam pre používateľské dopyty. Keď pavúk prehľadáva webovú stránku, vyhodnocuje množstvo faktorov vrátane štruktúry stránky, relevantnosti obsahu, použitia kľúčových slov a signálov používateľského zážitku. Tieto informácie sú potom uložené v obrovských indexoch, ktoré vyhľadávače používajú na priraďovanie dopytov používateľov k najrelevantnejším výsledkom. Kvalita a frekvencia prehľadávania pavúkom priamo ovplyvňuje, ako rýchlo sa nový obsah objaví vo výsledkoch vyhľadávania a ako presne môžu vyhľadávače stránky hodnotiť. Vyhľadávače ako Google, Bing, Baidu a Yahoo prevádzkujú vlastné proprietárne pavúky – Googlebot, Bingbot, Baiduspider a Slurp – každý s unikátnymi algoritmami a stratégiami optimalizovanými pre ciele a používateľskú základňu svojho vyhľadávača.
| Pavúk (bot) | Vyhľadávač | Primárna funkcia | Stratégia prehľadávania | Kľúčové vlastnosti |
|---|---|---|---|---|
| Googlebot | Indexuje webové stránky pre Google Search | Distribuované prehľadávanie s mobilnou aj desktopovou verziou | Podpora JavaScriptu, uprednostňuje indexovanie pre mobily, rešpektuje crawl budget | |
| Bingbot | Microsoft Bing | Indexuje webové stránky pre Bing Search | Paralelné prehľadávanie na viacerých serveroch | Efektívne využitie šírky pásma, rešpektuje robots.txt, podpora viacerých typov obsahu |
| Baiduspider | Baidu | Indexuje webové stránky pre Baidu Search | Optimalizované pre čínsky jazykový obsah | Špecializovaný na ázijský web, podporuje zjednodučenú aj tradičnú čínštinu |
| DuckDuckBot | DuckDuckGo | Indexuje webové stránky pre vyhľadávanie zamerané na súkromie | Ohľaduplné prehľadávanie s dôrazom na súkromie | Minimálne zbieranie údajov, rešpektuje preferencie súkromia používateľov |
| YandexBot | Yandex | Indexuje webové stránky pre Yandex Search | Distribuované prehľadávanie s regionálnou optimalizáciou | Optimalizované pre ruský a východoeurópsky obsah |
Vlastníci webových stránok majú k dispozícii viacero nástrojov a stratégií na optimalizáciu toho, ako pavúky prechádzajú a indexujú ich obsah. Vytvorenie komplexného súboru sitemap.xml poskytuje pavúkom jasnú mapu všetkých stránok, ktoré treba indexovať, čo výrazne zlepšuje efektivitu prehľadávania a zaručuje, že žiadna dôležitá stránka nebude vynechaná. Optimalizácia meta tagov, vrátane titulkov a meta popisov, pomáha pavúkom porozumieť obsahu stránky a zlepšuje vzhľad stránok vo výsledkoch vyhľadávania. Implementácia dobre štruktúrovaného súboru robots.txt umožňuje vlastníkom stránok usmerniť pavúky k dôležitému obsahu a zároveň zabrániť indexovaniu stránok, ktoré by nemali byť verejne dostupné, ako sú admin panely alebo duplicitný obsah. Pravidelné pridávanie nového a aktualizovaného obsahu motivuje pavúky k častejším návštevám, udržiava indexy aktuálne a zlepšuje viditeľnosť vo vyhľadávaní. Vlastníci by mali zabezpečiť aj čistú a logickú architektúru webu s jasnou hierarchiou navigácie, aby pavúky ľahko objavili všetky stránky. Zlepšenie rýchlosti načítania stránok je kľúčové, pretože pavúky majú obmedzený crawl budget – teda množstvo zdrojov, ktoré vyhľadávače prideľujú na prehľadávanie konkrétnej stránky – a rýchlejšie stránky umožnia pavúkom prejsť viac obsahu v rámci tohto rozpočtu.
Napriek svojej vyspelosti čelia webové pavúky mnohým technickým výzvam, ktoré môžu obmedziť ich efektivitu. Dynamický obsah generovaný JavaScriptom predstavuje významnú prekážku, keďže nie všetky pavúky dokážu vykonať JavaScript na zobrazenie stránky tak, ako ju vidí používateľ. Obmedzenia rýchlosti, ktoré určujú weby, limitujú počet požiadaviek, ktoré môžu pavúky v danom čase urobiť, čo môže znemožniť úplné indexovanie veľkých stránok. CAPTCHA a iné anti-bot opatrenia môžu pavúkom zabrániť v prístupe k obsahu, aj keď legitimné pavúky vyhľadávačov sú zvyčajne na bielych listinách. Duplicitný obsah na viacerých URL môže zmiasť pavúky, ktorú verziu majú indexovať a hodnotiť, čo môže znížiť viditeľnosť vo vyhľadávaní. “Crawler traps” – úmyselné alebo náhodné nekonečné slučky v štruktúre webu – môžu zbytočne spotrebovať zdroje pavúka a crawl budget bez produktívneho indexovania. Navyše, s exponenciálnym rastom webového obsahu pavúky nemôžu prejsť a indexovať všetko, a preto používajú sofistikované algoritmy na určenie, ktorý obsah je najdôležitejší. Stránky chránené heslom a autentifikovaný obsah zostávajú pre verejné pavúky vo veľkej miere neprístupné, čo obmedzuje indexovanie súkromného alebo členského obsahu.
Technológia webových pavúkov sa neustále rýchlo vyvíja, ako rastie internet a stáva sa zložitejším. Moderné pavúky sú čoraz schopnejšie spracovávať pokročilé webové technológie vrátane single-page aplikácií, progresívnych webových aplikácií a dynamického renderovania obsahu. Do algoritmov pavúkov sú integrované umelá inteligencia a strojové učenie, aby lepšie chápali kontext obsahu, úmysel používateľa a kvalitu stránky. Nástup generatívnej AI vytvoril nové nároky na webové prehľadávanie, keďže AI systémy vyžadujú neustále aktualizované, relevantné a presné informácie na efektívne fungovanie. Firemné webové prehľadávače sú čoraz sofistikovanejšie, čo umožňuje podnikom prehľadávať vlastné weby na účely interného vyhľadávania, správy obsahu a monitorovania výkonnosti. Dôraz na efektivitu prehľadávania sa s rastom a zložitosťou webov zintenzívňuje – pavúky dnes implementujú inteligentnejšie algoritmy prioritizácie, aby maximalizovali hodnotu každého požiadavku na prehľadávanie. Vývoj pavúkov ovplyvňujú aj požiadavky na ochranu súkromia, s dôrazom na rešpektovanie súkromia používateľov pri efektívnom objavovaní a indexovaní obsahu. Do budúcnosti sa dá očakávať, že webové pavúky budú ešte inteligentnejšie a efektívnejšie, využijú pokročilé technológie na navigáciu v čoraz zložitejšom digitálnom prostredí a zároveň budú rešpektovať zásady webových stránok a súkromie používateľov.
Tak ako webové pavúky systematicky prehľadávajú a indexujú celý web, PostAffiliatePro systematicky sleduje a optimalizuje každý affiliate vzťah vo vašej sieti. Naša pokročilá sledovacia technológia zabezpečuje, že žiadna provízia nezostane nezaznamenaná a žiadna príležitosť neunikne.
Pavúky sú boti vytvorení na spamovanie, ktoré môžu vašej firme spôsobiť veľa problémov. Zistite o nich viac v článku.
Počítačové pavúky sú špeciálne boty navrhnuté na spamovanie vašej emailovej adresy alebo webovej stránky. Na ochranu svojich stránok pred útokmi využívajte dete...
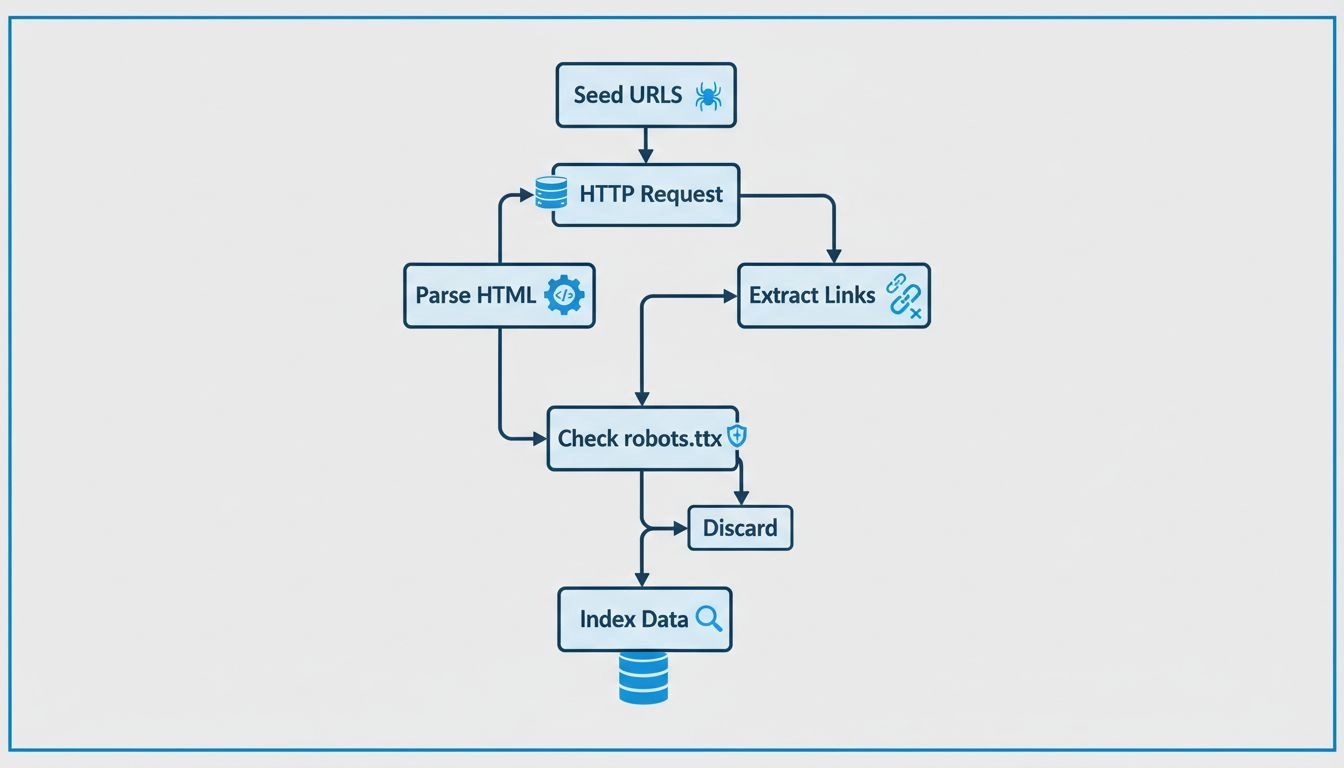
Zistite, ako fungujú webové prehľadávače – od počiatočných URL adries až po indexovanie. Pochopte technický proces, typy prehľadávačov, pravidlá robots.txt a vp...
Pridajte sa k našej komunite spokojných klientov a poskytujte vynikajúcu zákaznícku podporu s Post Affiliate Pro.
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.